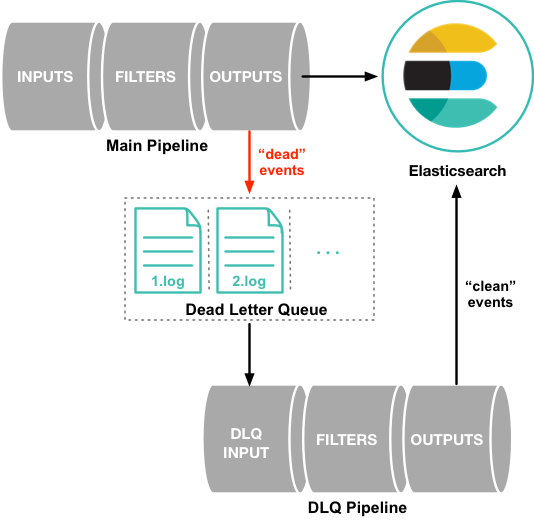
死信队列
注意:
死信队列功能仅支持 Elasticsearch 输出。此外,死信队列仅用于响应代码为400或404的情况,二者都是无法重试的事件。在将来的Logstash插件版本中将提供对其他输出的支持。在配置Logstash以使用此功能之前,请参阅输出插件文档以验证插件是否支持死信队列功能。
默认情况下,当事件由于数据包含映射错误或其他问题而无法处理时,Logstash管道会挂起或丢弃不成功的事件。为了防止在这种情况下丢失数据,您可以 配置Logstash 将不成功的事件写入死信队列,而不是丢弃它们。
写入死信队列的每个事件都包括原始事件,无法处理事件原因的元数据,写入事件的插件信息,以及事件进入死信队列的时间戳。
要处理死信队列中的事件,只需创建一个Logstash管道配置,该配置使用 dead_letter_queue 输入插件 从队列中读取。
有关详细信息,请参阅 处理死信队列中的事件。
启用死信队列
默认情况下,死信队列是禁用的。要启用死信队列,请在 logstash.yml 中设置 dead_letter_queue_enable 选项:
dead_letter_queue.enable: true
死信队列作为文件存储在Logstash实例的本地目录中。默认情况下,死信队列文件存储在 path.data/dead_letter_queue 中。每个管道都有一个单独的队列。例如,主管道的死信队列默认存储在 LOGSTASH_HOME/data/dead_letter_queue/main 中。队列文件按顺序编号:1.log,2.log 等。
您可以在 logstash.yml 文件中设置 path.dead_letter_queue,以指定文件的不同路径:
path.dead_letter_queue: "path/to/data/dead_letter_queue"
注意: 您最好不要为两个不同的Logstash实例使用相同的
dead_letter_queue路径。
文件轮换
死信队列具有内置的文件轮换策略,用于管理队列的文件大小。当文件大小达到预配置阈值时,将自动创建新文件。
默认情况下,每个死信队列的最大大小设置为1024mb。要更改此设置,请使用 dead_letter_queue.max_bytes 选项。如果储存的条目超过此设置的大小,则会删除条目。
处理死信队列中的事件
当您准备处理死信队列中的事件时,可创建一个使用 dead_letter_queue 输入插件 从死信队列中读取的管道。您使用的管道配置取决于需要做什么。例如,如果死信队列包含由Elasticsearch中的映射错误导致的事件,则可以创建读取"死"事件的管道,删除导致映射问题的字段,并将干净事件重新索引到Elasticsearch中。
以下示例显示了一个简单的管道,它从死信队列中读取事件,并将事件(包括元数据)写入标准输出:
input {
dead_letter_queue {
path => "/path/to/data/dead_letter_queue" ①
commit_offsets => true ②
pipeline_id => "main" ③
}
}
output {
stdout {
codec => rubydebug { metadata => true }
}
}
① 包含死信队列的顶级目录的路径。此目录包含写入死信队列的每个管道的单独文件夹。要查找此目录的路径,请查看 logstash.yml。默认情况下,Logstash在用于持久存储的位置(path.data)下创建 dead_letter_queue目录,例如 LOGSTASH_HOME/data/dead_letter_queue。但是,如果设置了 path.dead_letter_queue,则会使用该位置。
②如果为 true,则保存偏移量。当管道重新启动时,它将继续从它停止的位置读取,而不是重新处理队列中的所有项目。当您在死信队列中探索事件并希望多次迭代事件时,可以将 commit_offsets 设置为 false。
③写入死信队列的管道的ID。默认为 "main"。
有关另一个示例,请参阅 示例:处理具有映射错误的数据。
当管道处理完成死信队列中的所有事件时,它将继续运行并处理流入队列的新事件。这意味着您无需停止生产系统来处理死信队列中的事件。
注意: 如果无法正确处理,则
dead_letter_queue输入插件 发出的事件将不会重新提交到死信队列。
从时间戳读取
当您从死信队列中读取时,您可能不希望处理队列中的所有事件,尤其是在队列中存在大量旧事件的情况下。您可以使用 start_timestamp 选项从队列中的特定点开始处理事件。此选项将管道配置为根据进入队列的时间戳开始处理事件:
input {
dead_letter_queue {
path => "/path/to/data/dead_letter_queue"
start_timestamp => 2017-06-06T23:40:37
pipeline_id => "main"
}
}
对于此示例,管道开始读取在2017年6月6日23:40:37或之后传递到死信队列的所有事件。
示例:处理具有映射错误的数据
在此示例中,用户尝试索引包含geo_ip数据的文档,但无法处理,因为它包含映射错误:
{"geoip":{"location":"home"}}
索引失败,因为Logstash输出插件需要位置字段中的 geo_point 对象,但该值是字符串。失败的事件将写入死信队列,以及有关导致失败的错误的元数据:
{
"@metadata" => {
"dead_letter_queue" => {
"entry_time" => #<Java::OrgLogstash::Timestamp:0x5b5dacd5>,
"plugin_id" => "fb80f1925088497215b8d037e622dec5819b503e-4",
"plugin_type" => "elasticsearch",
"reason" => "Could not index event to Elasticsearch. status: 400, action: [\"index\", {:_id=>nil, :_index=>\"logstash-2017.06.22\", :_type=>\"doc\", :_routing=>nil}, 2017-06-22T01:29:29.804Z My-MacBook-Pro-2.local {\"geoip\":{\"location\":\"home\"}}], response: {\"index\"=>{\"_index\"=>\"logstash-2017.06.22\", \"_type\"=>\"doc\", \"_id\"=>\"AVzNayPze1iR9yDdI2MD\", \"status\"=>400, \"error\"=>{\"type\"=>\"mapper_parsing_exception\", \"reason\"=>\"failed to parse\", \"caused_by\"=>{\"type\"=>\"illegal_argument_exception\", \"reason\"=>\"illegal latitude value [266.30859375] for geoip.location\"}}}}"
}
},
"@timestamp" => 2017-06-22T01:29:29.804Z,
"@version" => "1",
"geoip" => {
"location" => "home"
},
"host" => "My-MacBook-Pro-2.local",
"message" => "{\"geoip\":{\"location\":\"home\"}}"
}
要处理失败的事件,请创建以下管道,从死信队列中读取并删除映射问题:
input {
dead_letter_queue {
path => "/path/to/data/dead_letter_queue/" ①
}
}
filter {
mutate {
remove_field => "[geoip][location]" ②
}
}
output {
elasticsearch{
hosts => [ "localhost:9200" ] ③
}
}
① dead_letter_queue 输入插件 从死信队列中读取。
② mutate 过滤器删除名为 location 的问题字段。
③ clean事件被发送到Elasticsearch,可以将其编入索引,因为映射问题已得到解决。